



Kubernetes is a robust container orchestration platform that automates the deployment, scaling, and management of containerized applications. One of the fundamental aspects of Kubernetes is its ability to manage various types of workloads, which are essentially the applications running on the cluster. In Kubernetes, workloads are managed using different controllers such as Deployments, StatefulSets, DaemonSets, Jobs, and CronJobs. Each controller serves specific use cases and provides unique features that cater to different types of applications.
In this blog, we will delve deep into each workload type, discuss their use cases, and deployment strategies, and provide practical examples for deploying them in a Kubernetes cluster.
1. Deployments
Definition:
A Deployment in Kubernetes is a controller that provides declarative updates to applications. It manages the lifecycle of stateless applications, ensuring that the desired number of pod replicas are running at all times. Deployments are designed for scalable, high-availability applications and are ideal for managing stateless workloads.
Key Features and Benefits:
Rolling Updates: Deployments allow for seamless updates with zero downtime. Kubernetes gradually replaces old pods with new ones, ensuring that the application remains available during updates.
Rollback: If an update fails, Kubernetes can automatically roll back to the previous stable version.
Scaling: Deployments make it easy to scale applications horizontally by adjusting the number of pod replicas.
Self-healing: If a pod fails or gets deleted, Kubernetes automatically replaces it to maintain the desired state.
Use Cases:
Deploying web servers like NGINX or Apache.
Running microservices-based applications.
Hosting RESTful APIs.
Example Deployment Manifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.19
ports:
- containerPort: 80
Practical Task: Deploying and Managing a Deployment
Create the Deployment:
kubectl apply -f deployment.yamlCheck the Deployment Status:
kubectl get deploymentsScale the Deployment:
kubectl scale deployment nginx-deployment --replicas=5Update the Deployment Image:
kubectl set image deployment/nginx-deployment nginx=nginx:1.21Roll Back the Deployment:
kubectl rollout undo deployment/nginx-deployment
2. StatefulSets
Definition:
StatefulSets are specialized controllers for managing stateful applications that require stable, unique network identifiers and persistent storage. Unlike Deployments, which treat all pods as identical, StatefulSets maintain the order and identity of each pod, making them ideal for applications that need a fixed identity and stable storage.

Key Features and Benefits:
Stable Network Identity: Each pod in a StatefulSet has a unique name that is maintained across rescheduling.
Ordered Deployment and Scaling: Pods are created, updated, and deleted in a specific order. This is crucial for distributed systems where the order of operations matters.
Persistent Storage: StatefulSets work seamlessly with Persistent Volume Claims (PVCs) to ensure that each pod retains its data, even if it’s rescheduled.
Use Cases:
Running databases like MySQL, MongoDB, or Cassandra.
Managing distributed systems such as Apache Zookeeper or Kafka.
Deploying applications that require consistent storage and identity.
Example StatefulSet Manifest:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: "mysql"
replicas: 3
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
ports:
- containerPort: 3306
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: mysql-persistent-storage
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
Practical Task: Deploying a StatefulSet
Create the StatefulSet:
kubectl apply -f statefulset.yamlCheck the StatefulSet Status:
kubectl get statefulsetsAccess a Pod within the StatefulSet:
kubectl exec -it mysql-0 -- /bin/bashScale the StatefulSet:
kubectl scale statefulset mysql --replicas=5
3. DaemonSets
Definition:
DaemonSets ensures that a specific pod runs on all or selected nodes within a Kubernetes cluster. This is particularly useful for deploying system-level applications that need to run across every node, such as logging, monitoring, or security agents.
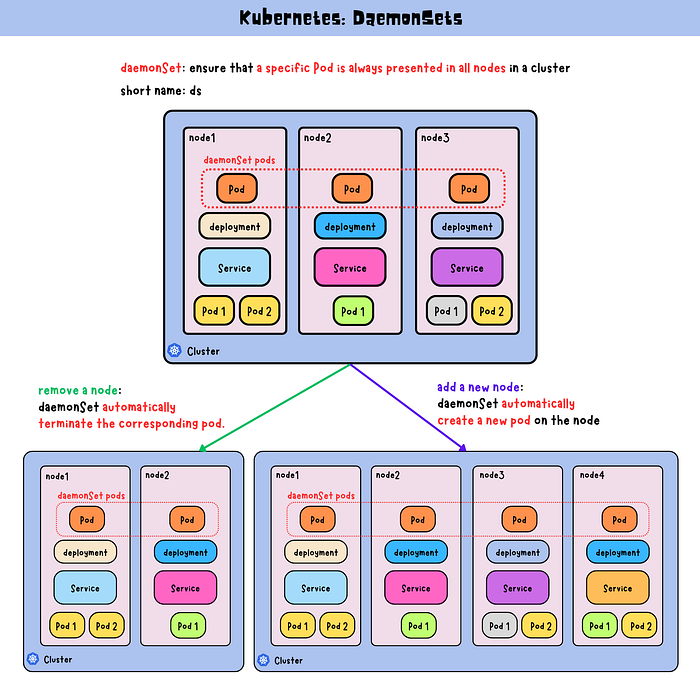
Short Name: ds
$ kubectl api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
daemonsets ds apps/v1 true DaemonSet
Key Features and Benefits:
Uniform Deployment: DaemonSets ensure that the specified pods are deployed uniformly across all nodes or a subset of nodes.
Efficient Resource Usage: Since DaemonSets are deployed on every node, they can efficiently utilize resources, ensuring that critical services are always available.
Automatic Updates: When a new node is added to the cluster, DaemonSets automatically deploys the required pods to the new node.
Use Cases:
Deploying logging agents like Fluentd or Logstash on all nodes.
Running network monitoring tools such as Prometheus Node Exporter.
Implementing security agents across the cluster.
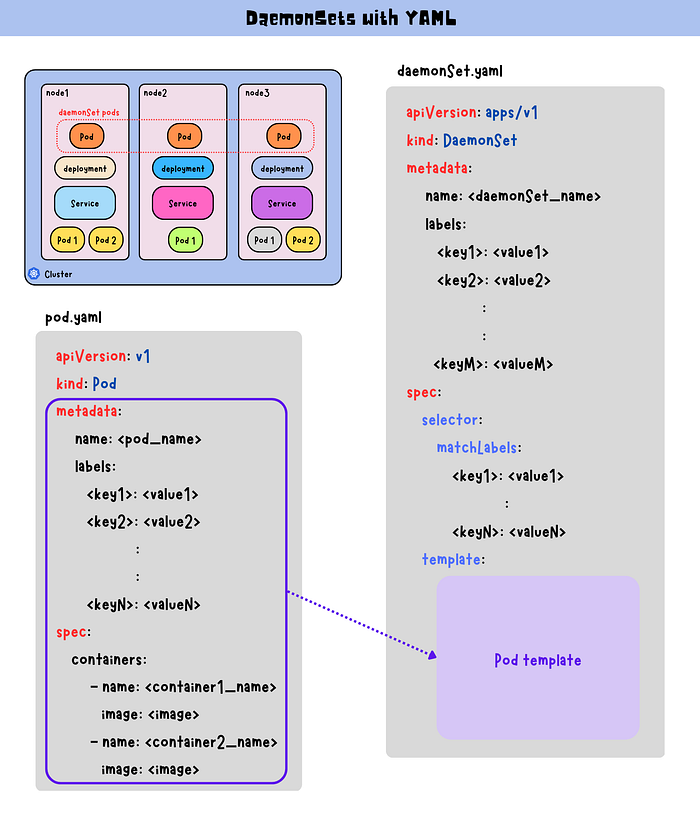
Example DaemonSet Manifest:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
labels:
app: fluentd
spec:
selector:
matchLabels:
name: fluentd
template:
metadata:
labels:
name: fluentd
spec:
containers:
- name: fluentd
image: fluentd:latest
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
Practical Task: Deploying a DaemonSet
Create the DaemonSet:
kubectl apply -f daemonset.yamlCheck the DaemonSet Status:
kubectl get daemonsetsVerify Pods on All Nodes:
kubectl get pods -o wideDelete the DaemonSet:
kubectl delete daemonset fluentd
4. Jobs
Definition:
A job in Kubernetes involves managing a one-time or finite task. It creates one or more pods and ensures that a specified number of them are completed. Jobs are ideal for tasks that need to be run to completion, rather than long-running services.
Key Features and Benefits:
Guaranteed Completion: Jobs ensure that the specified number of pods complete their tasks.
Parallelism: Jobs can run multiple pods in parallel, speeding up the execution of tasks.
Retry Mechanism: Kubernetes automatically retries pods if they fail, up to a configurable limit.
Use Cases:
Running batch processing tasks.
Performing data transformations or migrations.
Generating reports or analytics.
Example Job Manifest:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
Practical Task: Deploying a Job
Create the Job:
kubectl apply -f job.yamlCheck the Job Status:
kubectl get jobsView the Job Logs:
kubectl logs job/piDelete the Job:
kubectl delete job pi
5. CronJobs
Definition:
CronJobs in Kubernetes allows for the management of time-based tasks, similar to cron jobs in Unix-like systems. They create Jobs on a repeating schedule, making them perfect for tasks that need to run periodically.
CronJob Scheduling
The schedule for a CronJob in Kubernetes is specified using a cron expression. A cron expression consists of five fields separated by spaces:
Minute (0-59)
Hour (0-23)
Day of the month (1-31)
Month (1-12)
Day of the week (0-7) (0 or 7 is Sunday)
Creating a CronJob
A CronJob resource specifies how to run a job on a time-based schedule. The schedule format is the same as the Unix cron format.
Key Features and Benefits:
Scheduled Execution: CronJobs can be scheduled to run at specific intervals, defined using cron syntax.
Automated Management: Kubernetes automatically manages the execution of CronJobs, including retries and failures.
Efficient Resource Usage: CronJobs only consumes resources when they run, making them resource-efficient for periodic tasks.
Use Cases:
Scheduling database backups.
Running periodic clean-up scripts.
Sending out scheduled reports or notifications.
Example CronJob Manifest:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from Kubernetes cluster
restartPolicy: OnFailure
Deploying a CronJob:
kubectl apply -f cronjob.yaml